I wanted to run a simple benchmark of two common stacks as a way to get a sense of baselines between Python and Rust for a backend web server. For Python, a common choice is FastAPI and SQLAlchemy. For Rust, a common choice is Axum and SQLx. How do they compare?
At least two similar comparisons have been made.
I wanted to do things slightly differently.
Coleman’s approach uses only a single CPU with limits the benefits of concurrency. It also doesn’t interact with a database.
Prokopiou’s approach is much more “real”. In fact, a little too “real” as to make the codebase a bit harder to quickly grok.
I wanted something between these two: (1) still include a database in the hot path and (2) make the codebase as simple as possible.
The benchmark
Each web server implements a single endpoint that runs
SELECT * FROM "users" ORDER BY user_id LIMIT 100from a local, Dockerized Postgres database seeded with 2000 users and returns the result as JSON. I chose this query somewhat arbitrarily. It’s not particularly interesting if the database query time dominates the time so much that the comparison is not useful (e.g., say we seeded 10k users and returned the entire list every time). But, it’s also not particularly interesting if there is no database interacting, since that’s what your basic CRUD backends always do some of.
Both use a connection pool of up to 5 connections, and both are based extremely closely on tutorial/example code from FastAPI and Axum.
Along the way, I got to try a handful of new HTTP benchmarking tools from this awesome list, and came across oha (also used by Prokopiou), and really enjoyed it.
That, along with btm, makes for very fun-to-watch interactive benchmarking.
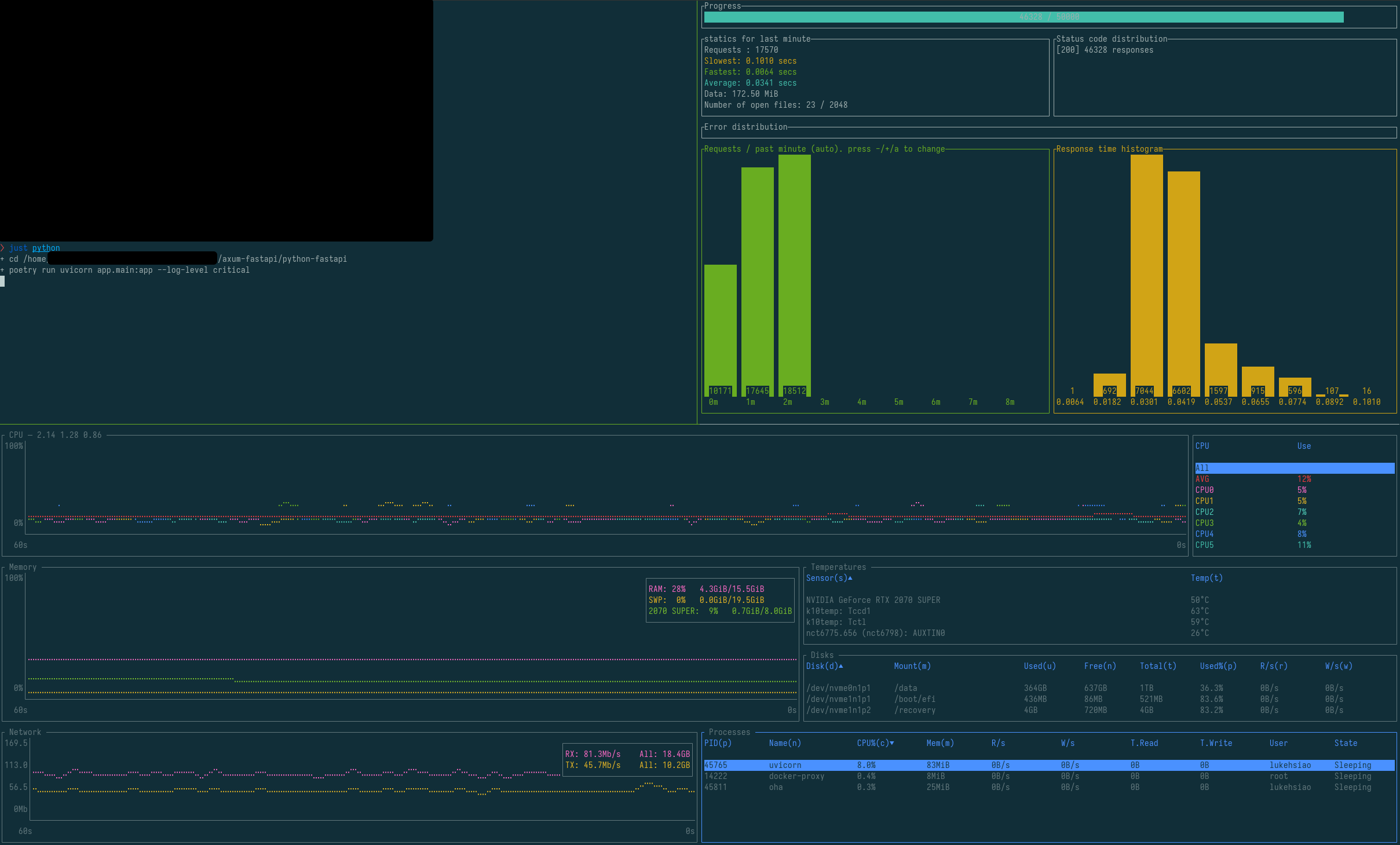
Results
⚠️ NOTE: The benchmarks have been updated with an asynchronous version of FastAPI and run on newer hardware. Please see the repository for updated results! ⚠️
On my personal PC with 16 GB of RAM and a Ryzen 7 3700X (8-core, 16-thread), I saw the following.
| Metric | FastAPI | Axum | Change (%) |
|---|---|---|---|
| Throughput (rps) | 305 | 9740 | +3090 |
| 50% latency (ms) | 30 | 1.0 | -97 |
| 99% latency (ms) | 74 | 1.4 | -98 |
| Peak Memory Usage (MiB) | 83 | 10 | -88 |
Dramatic improvements using Rust all around.
In particular, I was shocked at how large the latencies were for FastAPI, especially because this was running locally with no network latency.
Try it yourself
Please, go play with the code yourself!
In particular, please tell me if you think I’m doing something wrong or too unfair—benchmarks are hard! For example, I’m sure I have a coordinated omission problem on my hands, but I’m not quite sure what the most fair way to address it is.